

How illumex translates
your structured data into
meaningful business language
Need to get your data AI-Ready? Or augment your Governance? Or deploy LLMs reliably on top of your structured data? Here’s how illumex gets you to your goals—and fast.

90% of LLM deployments for structured data
fail to scale to production.
illumex makes sure that doesn’t happen to you.
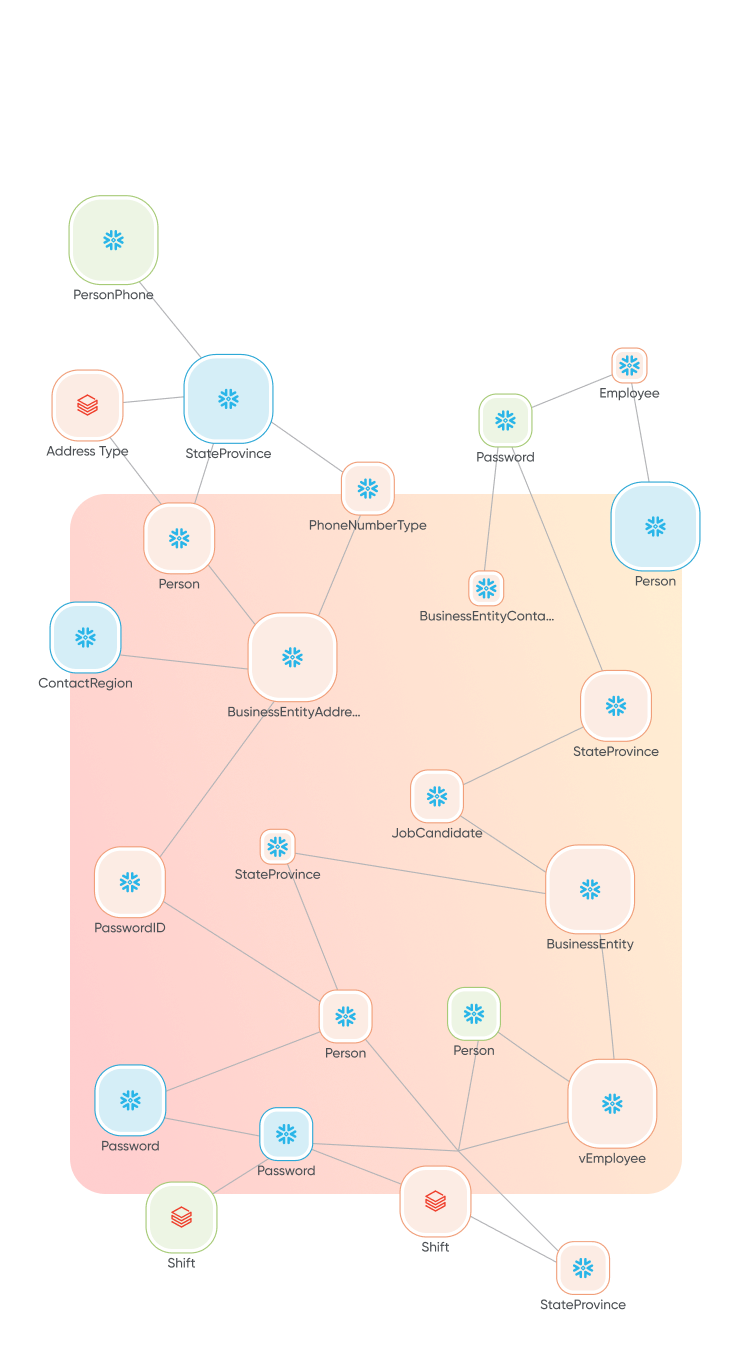
illumex’s proprietary platform, the Generative Semantic Fabric (GSF), combines semantic and graph models trained on industry business ontologies and retrained on your organization’s metadata.
This streamlined onboarding results in your automated organizational ontology, represented by a virtual knowledge graph of semantic embeddings.
GSF also includes an application layer consisting of:
✔ Auto-generated Data Dictionary
✔ Business Glossary
✔ Lineage
✔ Tagging
✔ SDK for LLM deployment
✔ and Governance workflows
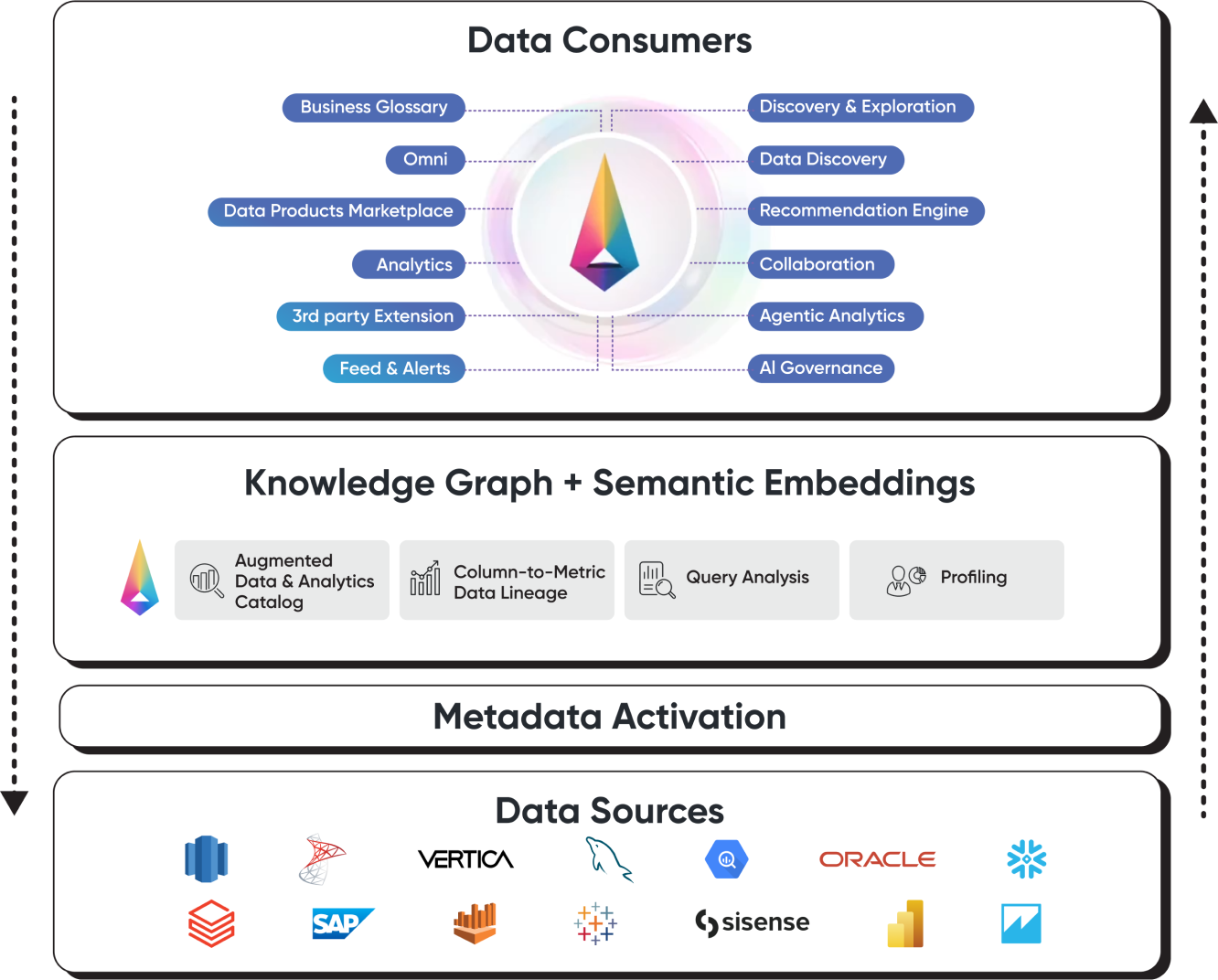
At the same time, illumex also acts as a Retrieval: interpreting users’ questions and their intent and matching them with deterministic, governed semantics in the prebuilt context—with flawless precision.
This automated Augmentation-Retrieval process, with built-in governance, ensures your LLM users make decisions with confidence—as the responses they get are always explained and hallucination-free.
With illumex handling the end-to-end implementation for you, you can now get multiple use cases off the ground and to production significantly faster by:
✔ Getting your data AI-Ready
✔ Augmenting AI Governance
✔ Deploying LLM analytics agents
AI-Ready Data
-
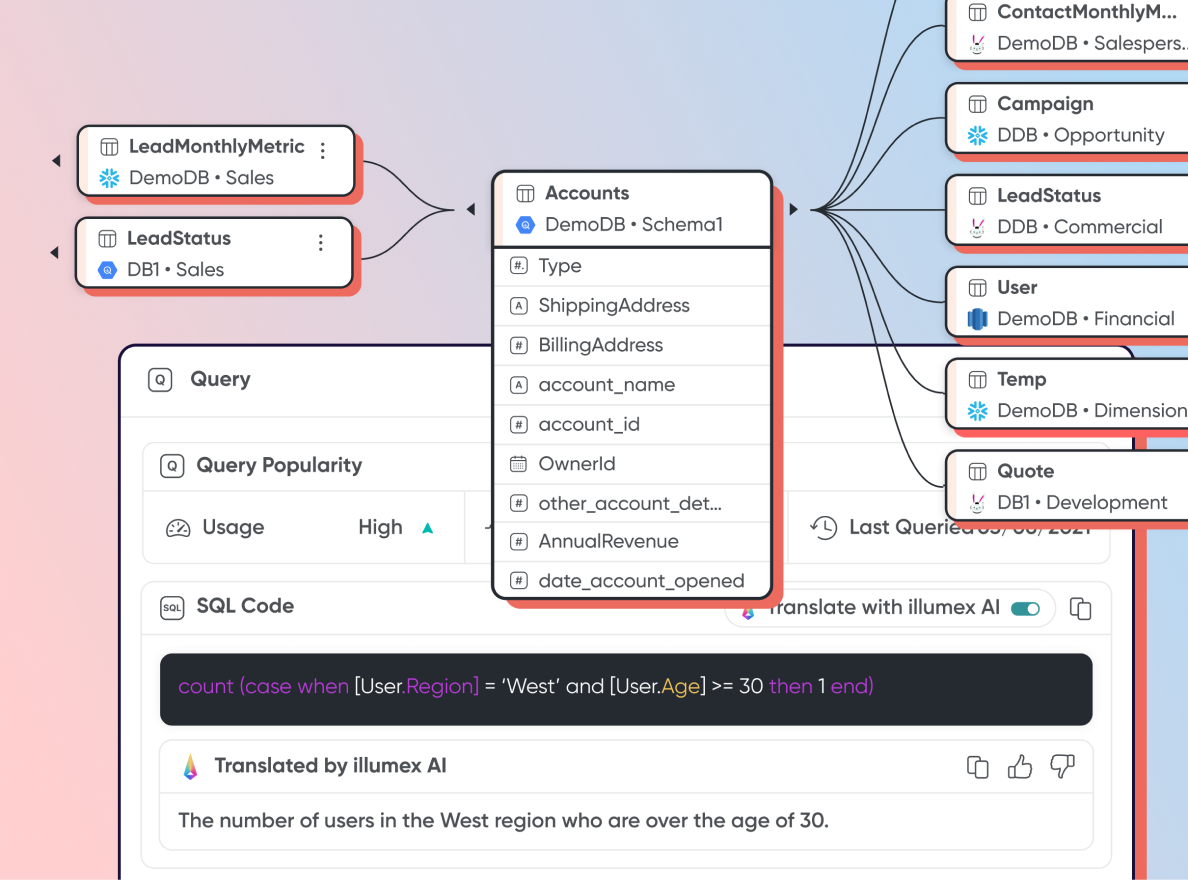
Augmented Data & Analytics DictionaryBenefits: Computing, storage, and data expert time costs are significantly reduced.Read moreillumex automatically maps all your structured data and its usage patterns into the data dictionary and suggests descriptions for easy documentation. At the same time, illumex identifies your most important assets so you can focus on them in line with your discovery, management, and governance efforts.

-
Column-to-Metric Data LineageBenefits: You can now plan ahead for changes while weighing the implications. At the same time, you’ll see a significant drop in investigation time for data failures.Read moreillumex ensures full mapping of any data asset and its origin, transformations, and destination. As a result, business terms and metrics are easily traceable to aggregated and raw data, allowing you to conduct RCA and impact analyses. illumex lineage spans from operation to analytics data sources to dashboards and business logic.
-
AI-Readiness AnalyticsBenefits: You can see exactly what you need to do to accelerate your journey to AI-Ready Data.Read moreYour illumex dashboard automatically reports on your data’s state of AI-readiness—indicating clearly where improvements are needed, and suggesting workflows to resolve them as swiftly as possible.
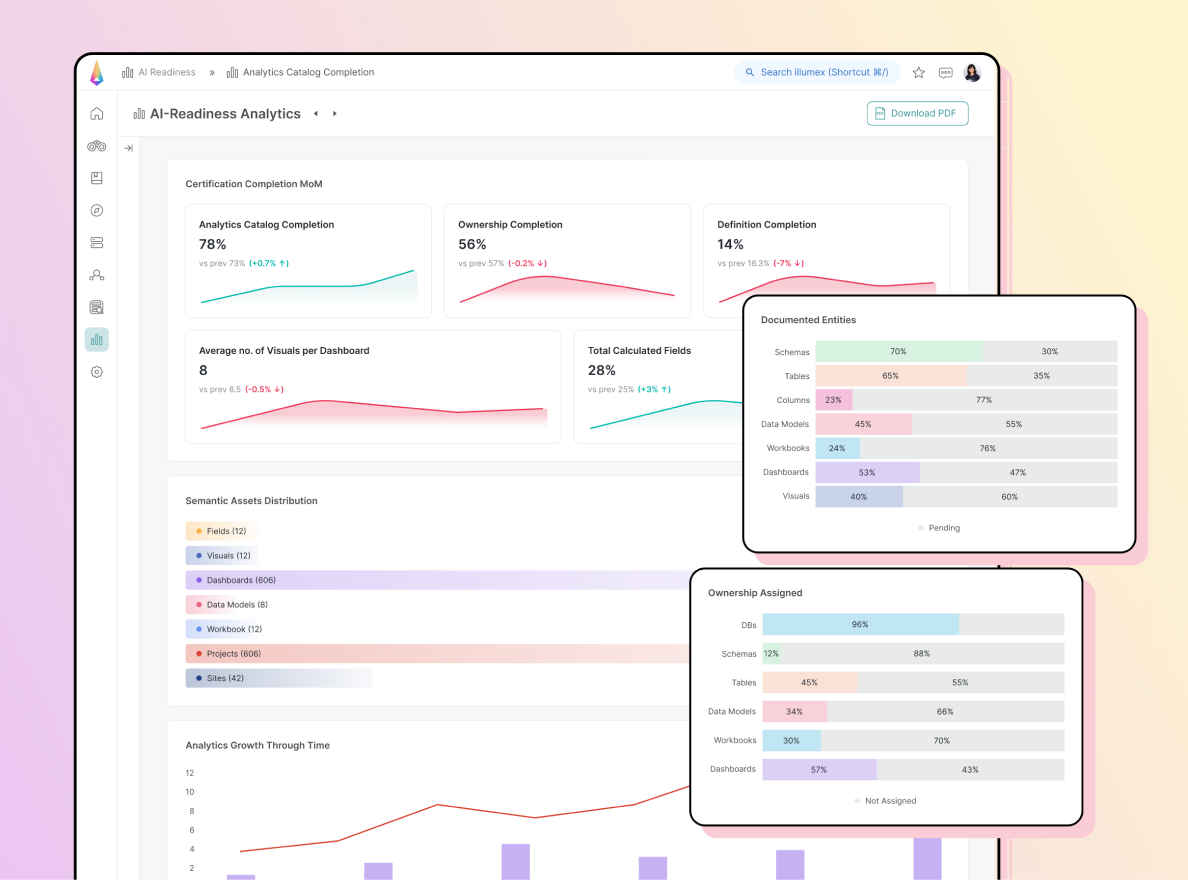
Augmented AI Governance
-
Auto-Generated Business GlossaryBenefits: Save up to 90% of your data team’s effort on governance, while building trust in data and semantics—for analytics and genAI.Read moreAs illumex discovers and maps your metadata to a virtual knowledge graph, it incorporates industry-specific business ontologies and your organization’s data stack — automatically generating a business glossary that includes Business Terms, their attributes, and Metrics. illumex also suggests descriptions for easy documentation, resulting in solid connections between business and data definitions.
-
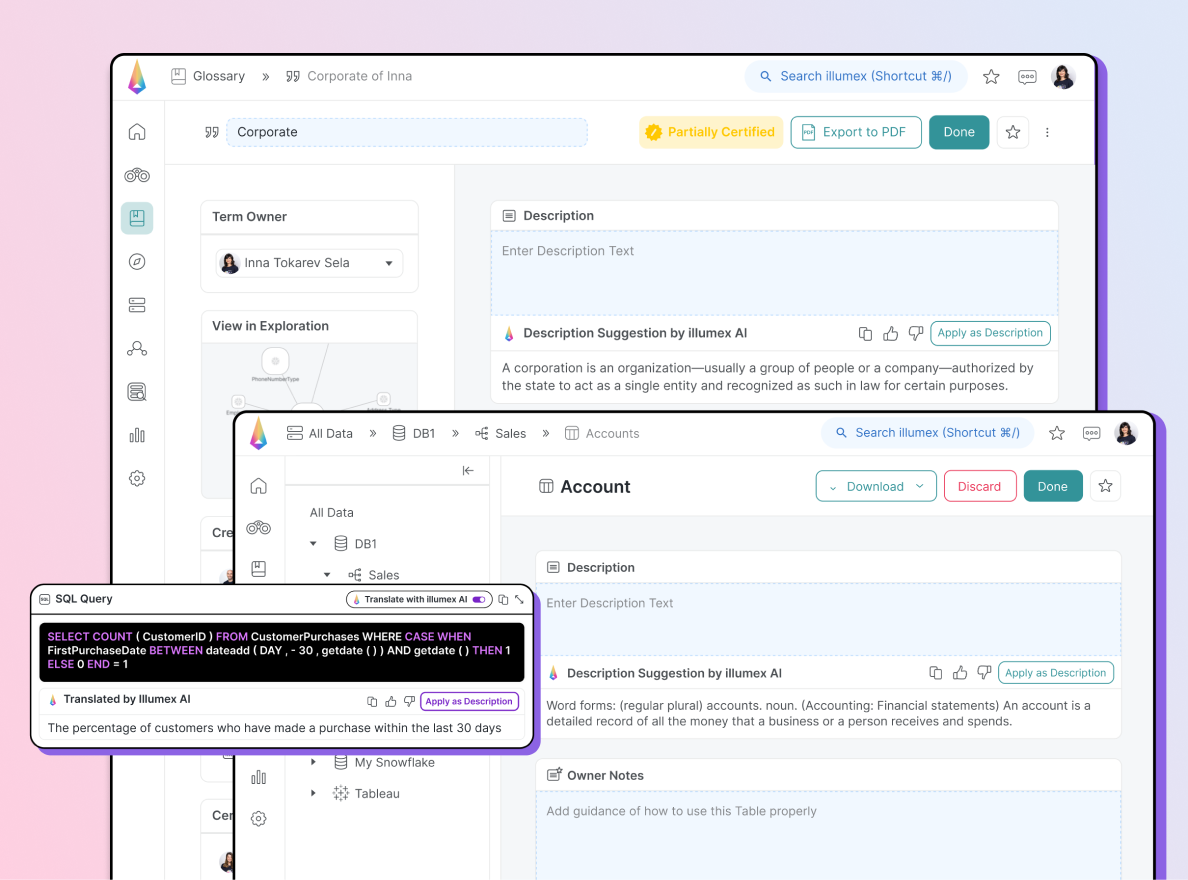
Suggested DocumentationBenefits: Maintaining an up-to-date knowledge base is now simple, easy, and painless.Read moreillumex suggests automated AI-generated descriptions for every entity in the system—based on each entity’s relationships, parents, children, usage context, and industry ontology. This covers everything from columns, tables, schemas, dashboards, and visuals on the Data Dictionary side to business terms, attributes, metrics, and analyses on the Business Glossary side.
-
Auto-TaggingBenefits: Save significant time and effort otherwise wasted manually tagging your metadata.Read moreillumex automatically finds and labels information based on your pre-defined rules and requirements. From creating rule-based tags using specific search criteria to flag sensitive information to identifying potentially sensitive or personal information (PII)—illumex does it all for you, including automatic updates whenever your metadata is scanned.
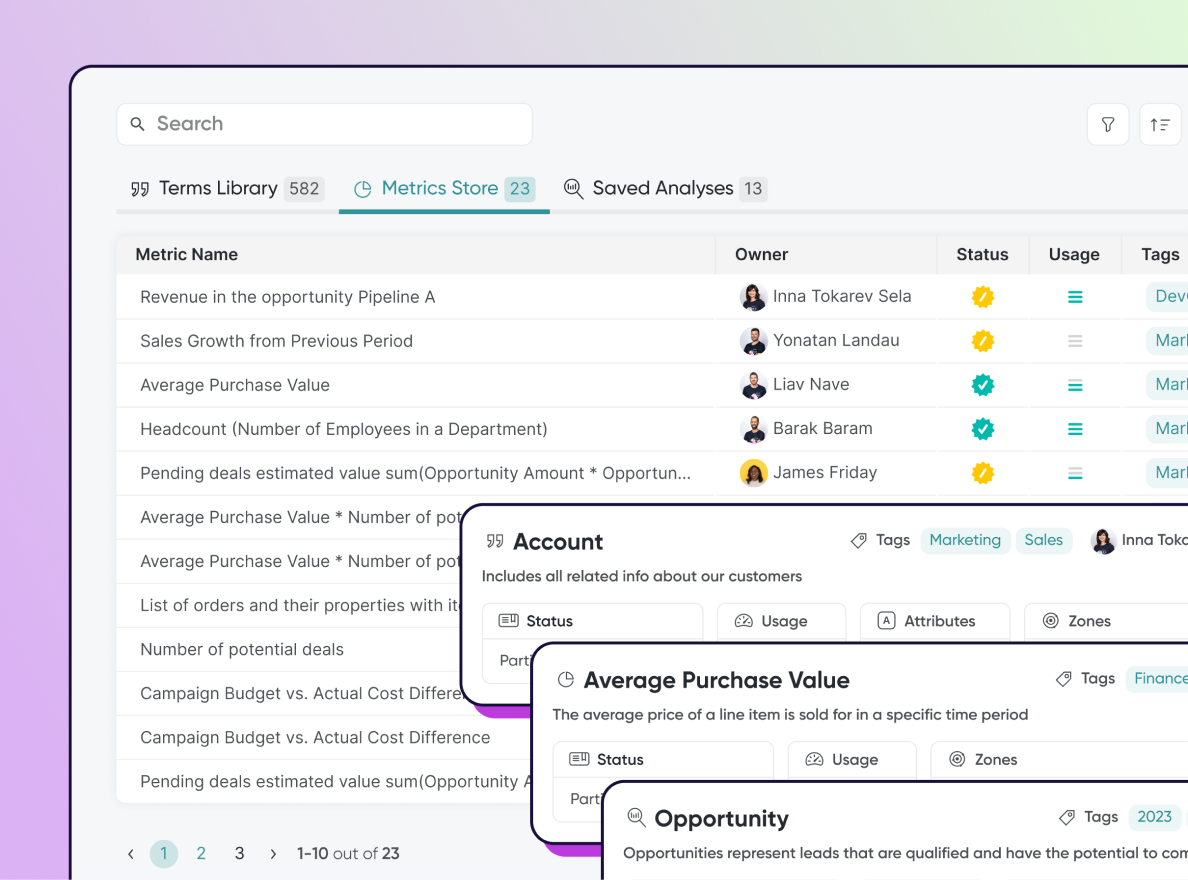
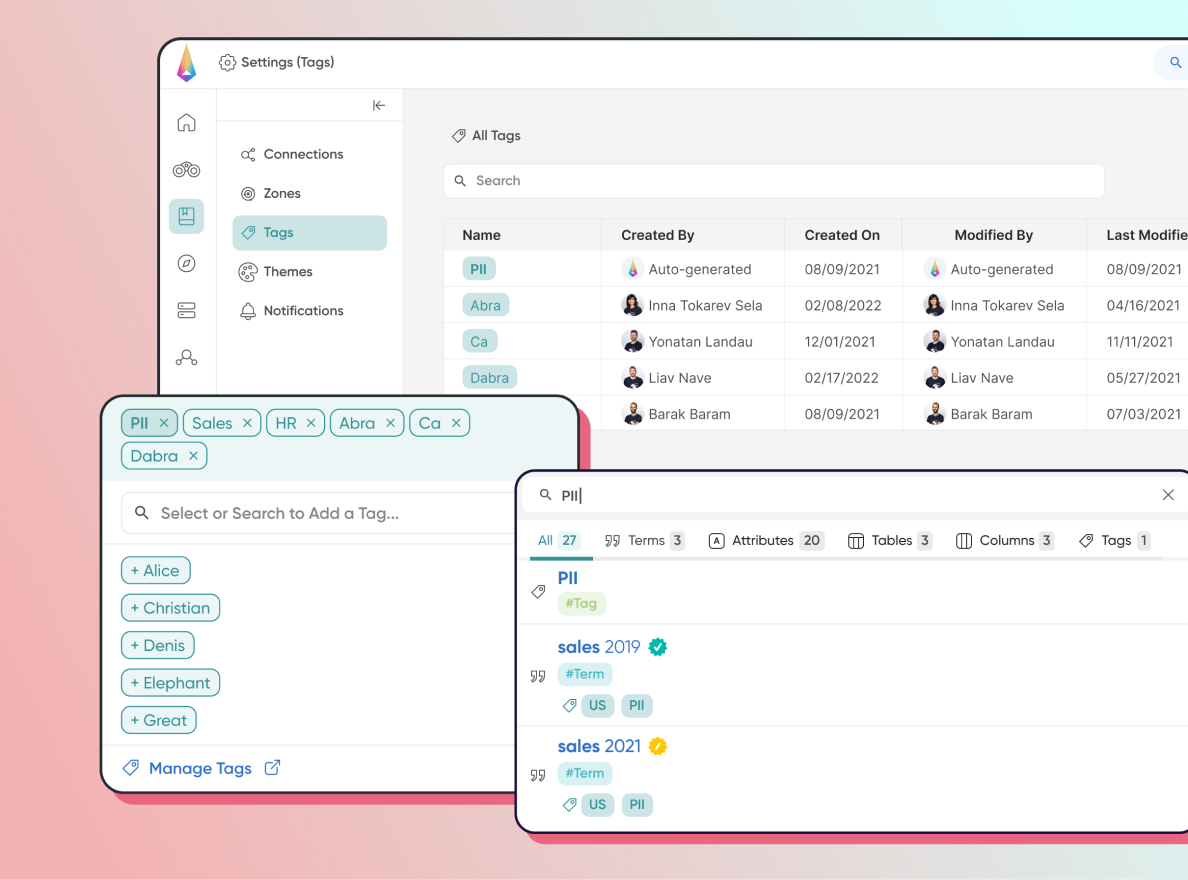
GenAI Agent Deployment
-
Automated Prebuilt ContextBenefits: Zero manual work is required to get ready for genAI deployment on top of your structured data.Read moreillumex automatically maps, labels, and enriches your metadata with semantic, business, and industry context, creating a virtual knowledge graph (your Generative Semantic Fabric). This architecture combines vector database and graph technology to automate context, reasoning creation, maintenance, and augment certification. This means you don’t need to spend months of manual work on RAG with genAI experts just to get deployment-ready.
-
Enterprise LLM GovernanceBenefits: 100% of answers LLM users receive are deterministic and hallucination-free—and the prompting process is transparent, explainable, and fully governed.Read moreillumex provides built-in LLM Governance for user prompts aligned with certified business definitions in your Business Glossary. This ensures deterministic, transparent, and explainable answers. The result is that when genAI agents work with your structured data, they interpret users’ questions and intent with flawless precision—matching them to the correct answer with zero hallucinations.
-
Self-Service Structured Data and Analytics Access via LLM AgentsBenefits: Any employee in your company can now make decisions 100% based on direct access to data and analytics—which are governed, explained, and trustworthy.Read moreWith illumex, when genAI analytics agents are deployed on top of your structured data, users will get precise, factual answers to their business-related data questions in the tools they’re working in—including Slack.


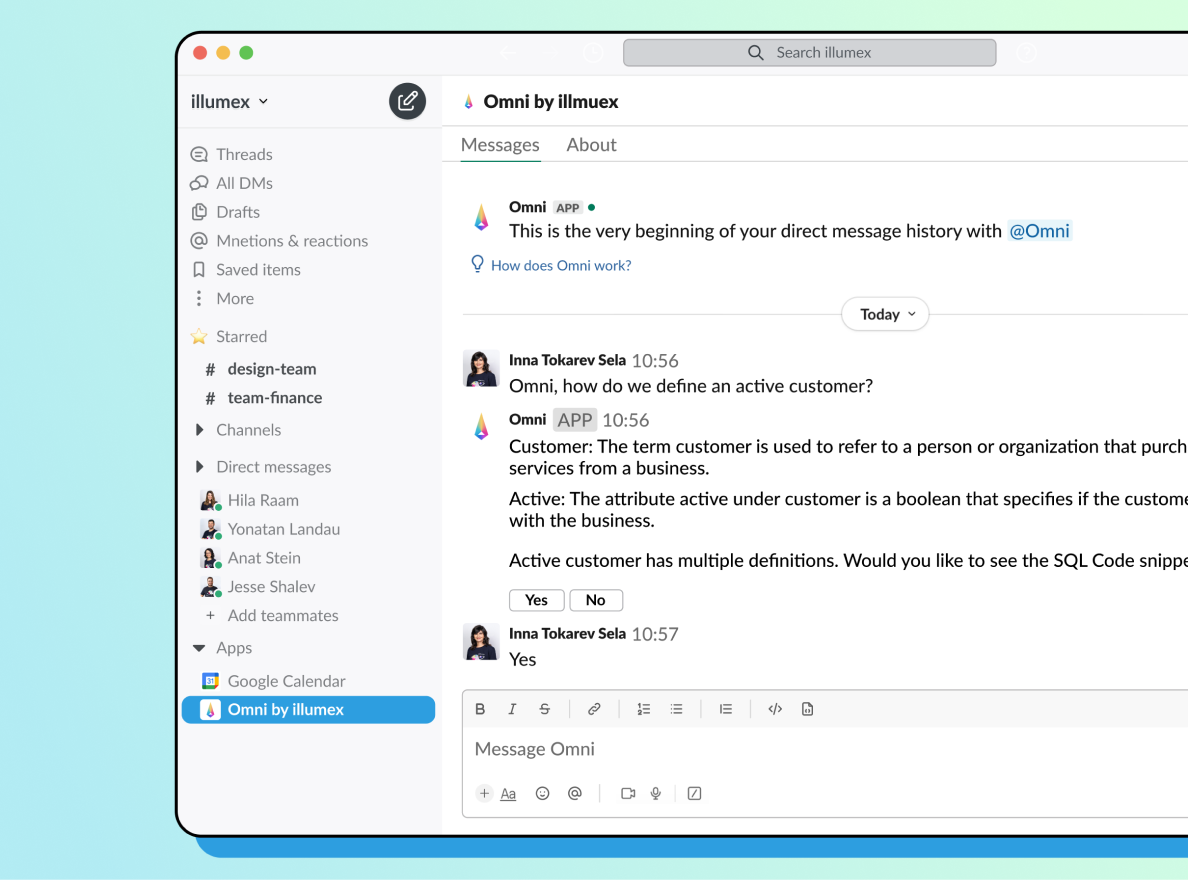
Cross-platform Features
-
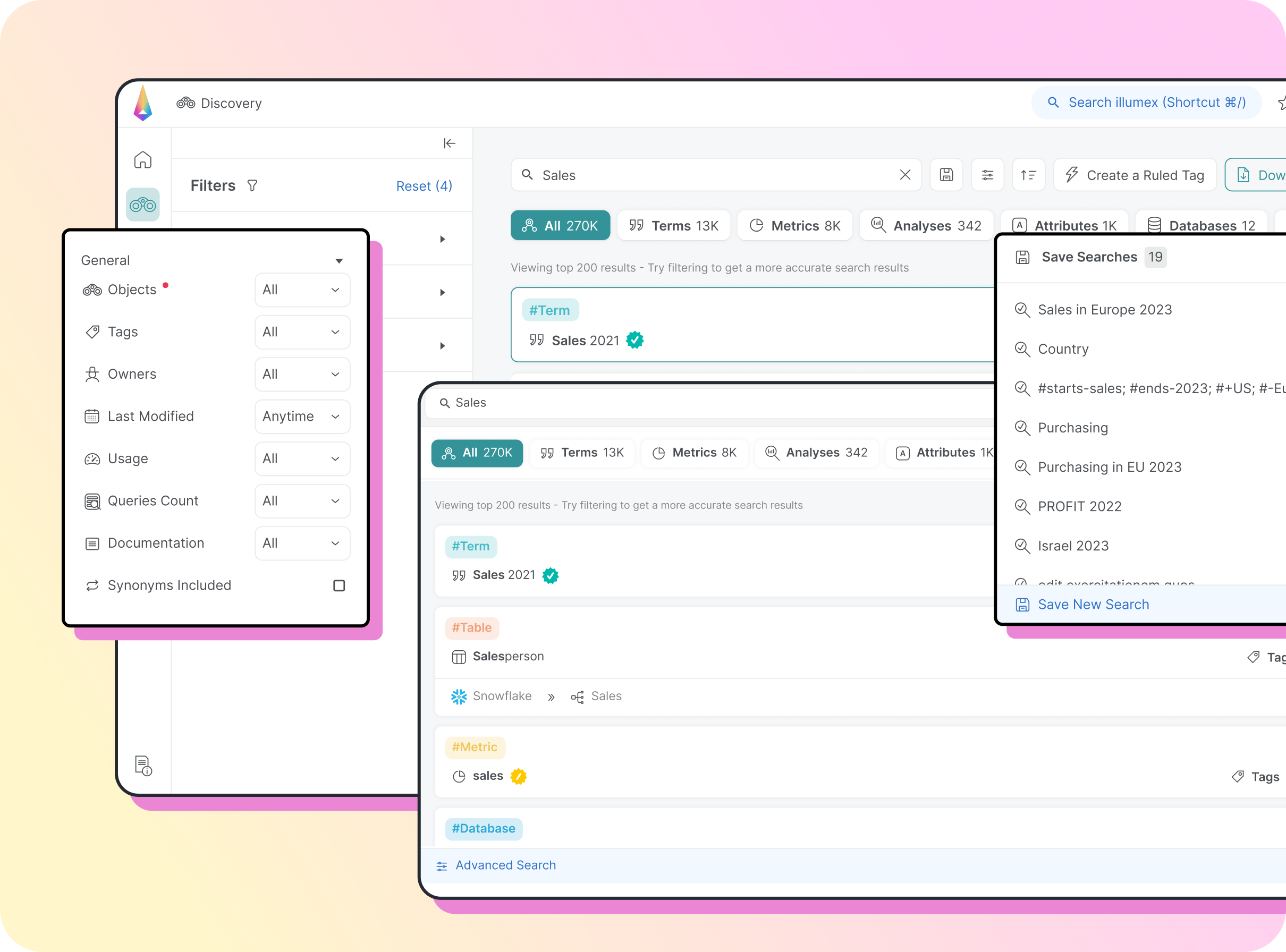
 Advanced Semantic DiscoveryBenefits: You now have full control over navigating your data landscape.Read more
Advanced Semantic DiscoveryBenefits: You now have full control over navigating your data landscape.Read moreDiscovery, illumex’s advanced semantic search, helps you refine results based on usage, data sources, timestamps, and more. Now, all the information you need—no matter how specific or complex—is at your fingertips instantly.
With the options for advanced filtering, saving searches, and accessing previous searches, your workflows and your data discovery process become simple.
-
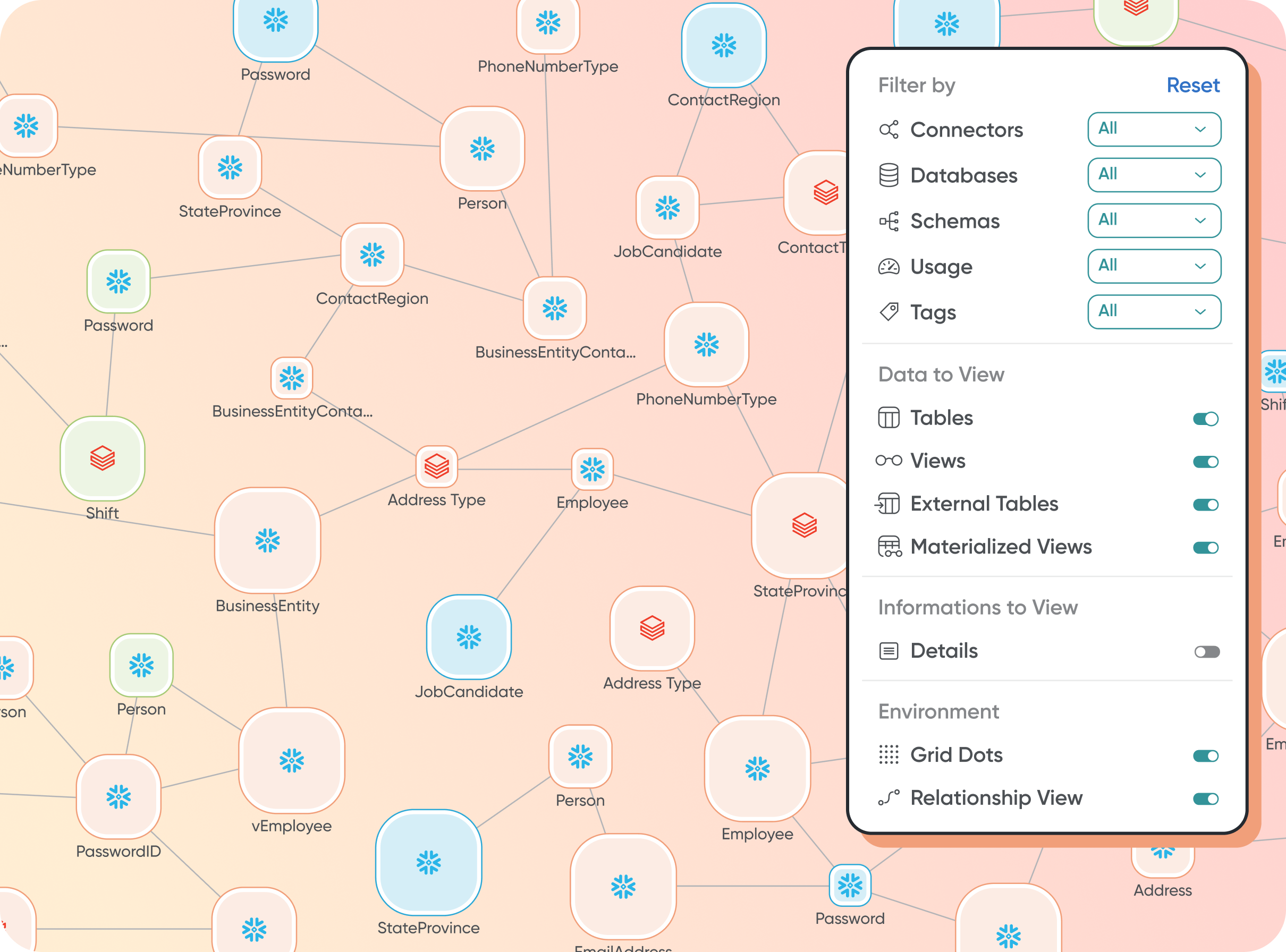
Ontology & TaxonomyBenefits: Gain deeper insights into your logic and data flows—effortlessly.Read more
illumex gives you a dynamic, visual graph of your semantic data ontology, showing the relationships between auto-generated and added semantic elements.
You can also easily trace the factors that impact metric calculations and explore your organizational taxonomy to learn how data consumers use your data across
teams. -
Feed & AlertsBenefits: Easily spot and fix mistakes ahead of time—before users stumble on them and lose trust in the system.Read more
illumex helps you stay on top of everything. Whenever data or semantic entity changes, the assigned owner gets a notification with all the details.
You’ll see exactly what changed and how it affects other entities. Plus, you’ll also get a direct link to this asset’ autogenerated column-level lineage, so you ca n quickly view everything downstream that’s impacted. -
CollaborationBenefits: Communication between data producers and data consumers flows seamlessly.Read more
The collaboration tool lets data engineering, analytics, and governance teams quickly open a shared discussion—while mentioning each other in the context of specific data or semantic assets. This ensures that context doesn’t get lost in translation across external project management tools that are not connected to the data or semantic environments.
-
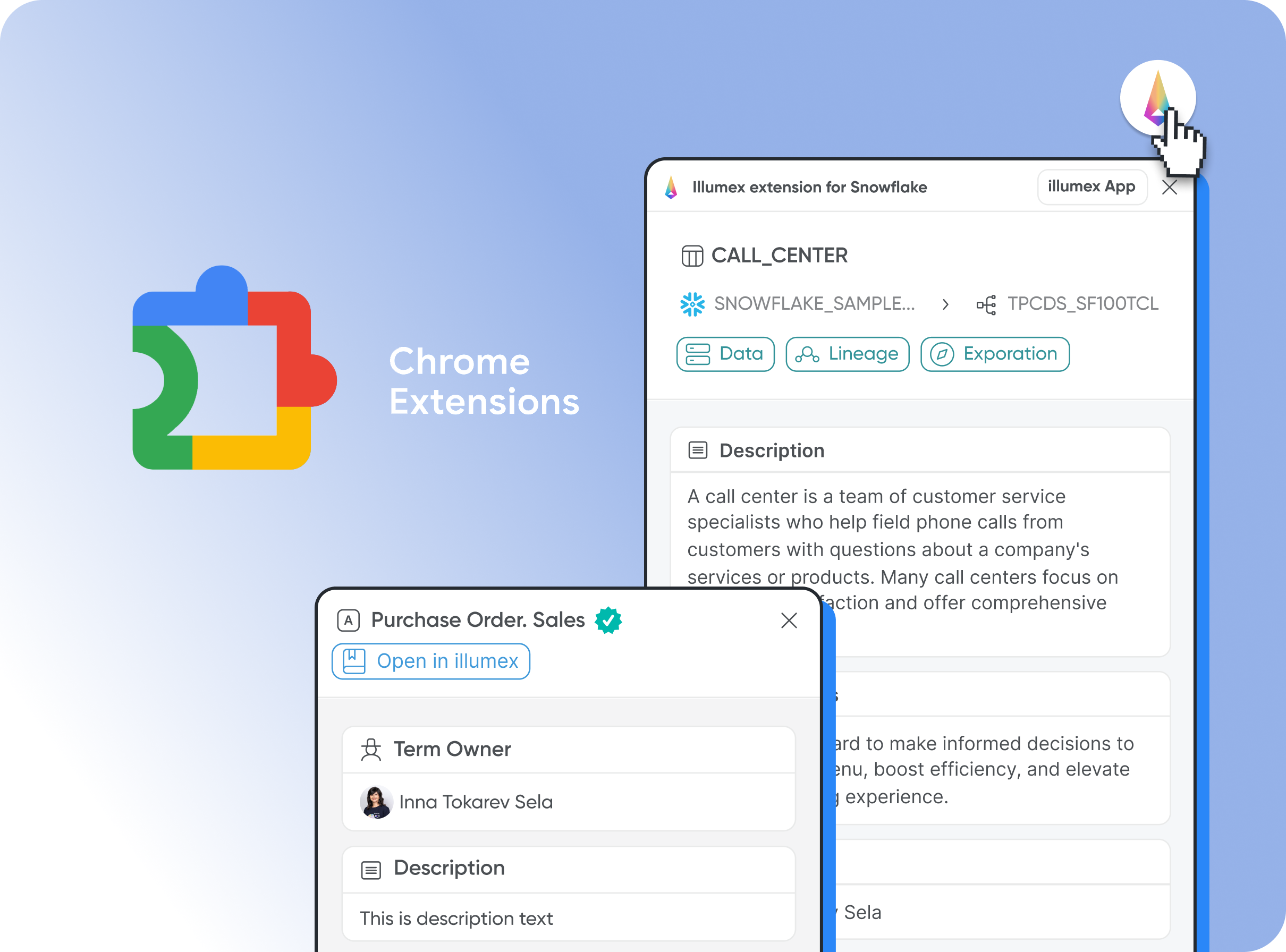
Web Extensions for ToolsBenefits: No matter which tools you’re using, illumex enables you to make decisions with them—with confidence, and wider context upstream or downstreamRead more
illumex comes with web extensions for multiple 3rd party tools, like Tableau and Snowflake. This allows you to pull in business and data context wherever you’re working so you can better understand the business logic, calculation, and data lineage behind the analytics and transformations.


Results you can see with illumex.
And only illumex.
-
 FASTEST TIME TO VALUEStart using the system in just 1 week
FASTEST TIME TO VALUEStart using the system in just 1 weekRAG/graphRAG and manual methods of context and reasoning augmentation take months to implement. Plus, you need highly skilled genAI experts to do it for you.
But illumex gets your organizational context and reasoning embedded and augmented for you—automatically—allowing you to start chatting with your data in days—not months.
-
 SELF-SERVICE DATA ACCESS FOR ALLMake 100% of your decisions with data
SELF-SERVICE DATA ACCESS FOR ALLMake 100% of your decisions with dataWith illumex, genAI agents that are deployed on top of your structured data deliver explainable, verifiable, and hallucination-free responses that everyone in your organization can trust. This means that every employee can now make data-based decisions, 100% of the time—without the need for special technical skills.
-
 GOVERNANCE AT SCALE90% faster governance processes
GOVERNANCE AT SCALE90% faster governance processesillumex automated documentation
generates business terms and documentation descriptions for you. Now, your organization’s structured data, analytics, AI, and genAI interactions are documented, certified, trackable, and explainable—all the time. -
 SUPERIOR EFFICIENCY80% less effort for data
SUPERIOR EFFICIENCY80% less effort for data
teamsAs soon as illumex is set up, it immediately discovers, maps, and interprets data across your databases, warehouses, data lakes, and BI applications—whether on-prem, in the cloud, or hybrid, with no extra effort on your part.








