


Why Your GenAI Can’t Afford to Hallucinate – and How to Prevent It
What’s at stake when your enterprise GenAI confidently spins fiction instead of facts?
Trust. Precision. Your reputation.
It’s not a “what if” situation. A Stanford study revealed that for verifiable legal queries, hallucination rates hover between a whooping 69% and 88%. And it’s not just law, either. Think finance. Healthcare. Pharma. In regulated industries such as these, trust and accuracy are non-negotiable.
GenAI hallucinations here are not a mere inconvenience. They can mean lawsuits, fines, and reputational damage that can take years to repair.
Here’s the good news: GenAI hallucinations are preventable. The bad news? The clock’s ticking.
But before we jump into solutions, let’s break down why these hallucinations happen in the first place. And why it’s critical to tackle them now, before the risks start writing your story.
Why GenAI Hallucinations Happen
AI hallucinations happen when GenAI has to piece together answers from incomplete, inconsistent, or context-blind data. Or worse, when it’s juggling conflicting sources answering the same question. Without semantic alignment or a clear “single source of truth,” GenAI fills the gaps.
It misinterprets, it guesses, and sometimes it fabricates. Simply put, it’s the model’s way of improvising when data is messy or misaligned with the task at hand.
The way organizations train, deploy, and connect GenAI models to their enterprise data is usually the culprit. Siloes, duplications, gaps everywhere. To bring value, GenAI needs to learn how to think like your business. But without proper context and AI-ready data, your model will stumble.
On top of that, off-the-shelf GenAI models don’t come with governance baked in. They weren’t built for the messy realities of enterprise applications. Sure, the vendors give you the bare minimum to get started. But they lack governance access controls and permission rights. So when it comes to things like protecting against data leakage, or dodging hallucinations – you’re on your own.
And that creates a perfect storm of risks, especially when combined with data that lacks semantics and context. Let’s break it down.
Poor Data Quality With no Reconciled Semantics
Ah, the mythical “single source of truth.” The idea that all your data lives harmoniously in one central hub. Sounds great, in theory. But reality has other plans. When every team uses different tools, different platforms, data silos emerge. And this dream of a unified hub? Poof – it’s gone.
For GenAI to actually give you useful responses, your data has to be semantically coherent. That’s a fancy way of saying it has to make sense everywhere – across teams, tools, and applications. Without reconciled semantics making sure your data speaks the same language everywhere, GenAI outputs won’t be accurate.
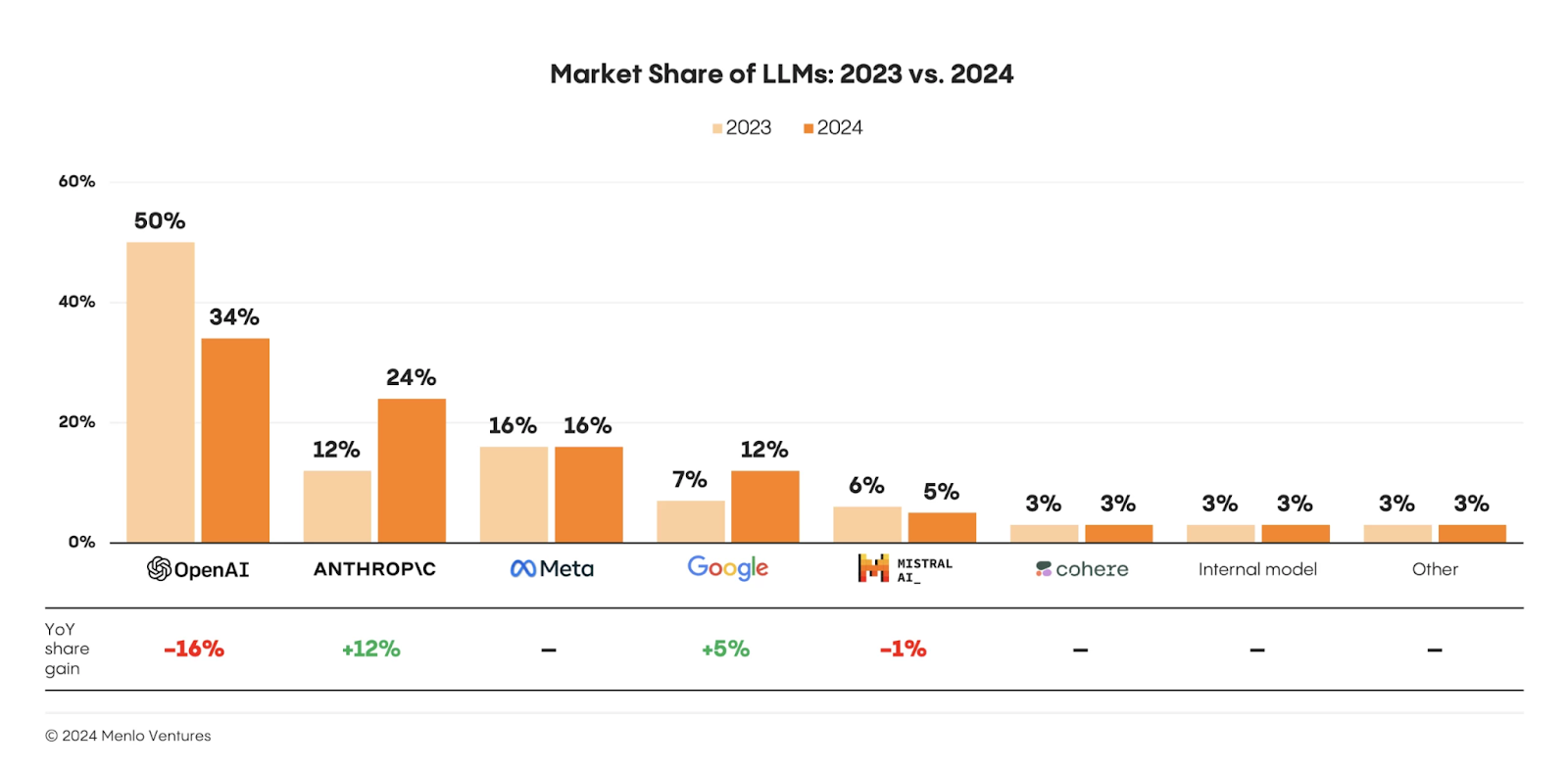
According to recent research by Menlo Ventures, Enterprises now use a multi-model approach instead of sticking to one provider. Research shows most organizations run three or more GenAI models, switching between them based on use case or results.
Generalized Training Data = Too Much Noise
Most off-the-shelf models are trained on publicly available internet data (think Wikipedia, Reddit, news websites, social media, etc). It’s fine for casual questions like “What’s the capital of France?” but for enterprises? It’s a disaster.
These models don’t understand your industry or your users. It’s not simply about semantics – it’s about understanding the meaning behind the words in the specific context of your field.
Let’s take the term “margins,” for example. In healthcare, they’re about patient care – low margins can lead to more hospital readmissions or even closures. In finance, margins are all about profits and investments. Same word, totally different story depending on the context.
Context matters. Whether it’s pharma, retail, or finance, a term’s meaning can shift entirely based on the industry or even the specific interaction. Gartner says that by 2027, over 50% of GenAI models in enterprises will speak the language of their industry or function. A leap from just 1% in 2023.
This isn’t surprising. After all, relying solely on generalized training data means you end up with GenAI that simply doesn’t understand your industry’s language. Which brings us to our next point.
Lots of Data… Missing (Your) Business Context
Your unique business context is the bridge between raw data and smart decisions. It’s what turns numbers into meaning, facts into action. Even when your data is semantically aligned, and has specific domain knowledge related to your field. Still, if it lacks business and usage context, your model can miss the mark. You ask a question and it’ll misunderstand your intent, giving you wrong answers.
To make GenAI work in enterprise settings, it must understand not just the words but the world in which they operate. Including the connections and relationships between concepts and terms in your data. It also needs to have a good grasp on how your particular organization works with the data. Your unique workflows and priorities. Your company’s distinct flair.
For GenAI answers to be precise, they must be rooted in your particular business logic and context. In other words, to bring real value, GenAI must “get” (and become fluent in) your natural business language.
Manual-Heavy Customization Techniques Like RAG
Some organizations turn to workarounds like Retrieval-Augmented Generation (RAG) or GraphRAG. Hoping to patch the gap by pulling in context and reasoning for their GenAI model.
In fact, RAG adoption has jumped to 51%, up from 31% last year, according to recent research by Menlo Ventures.
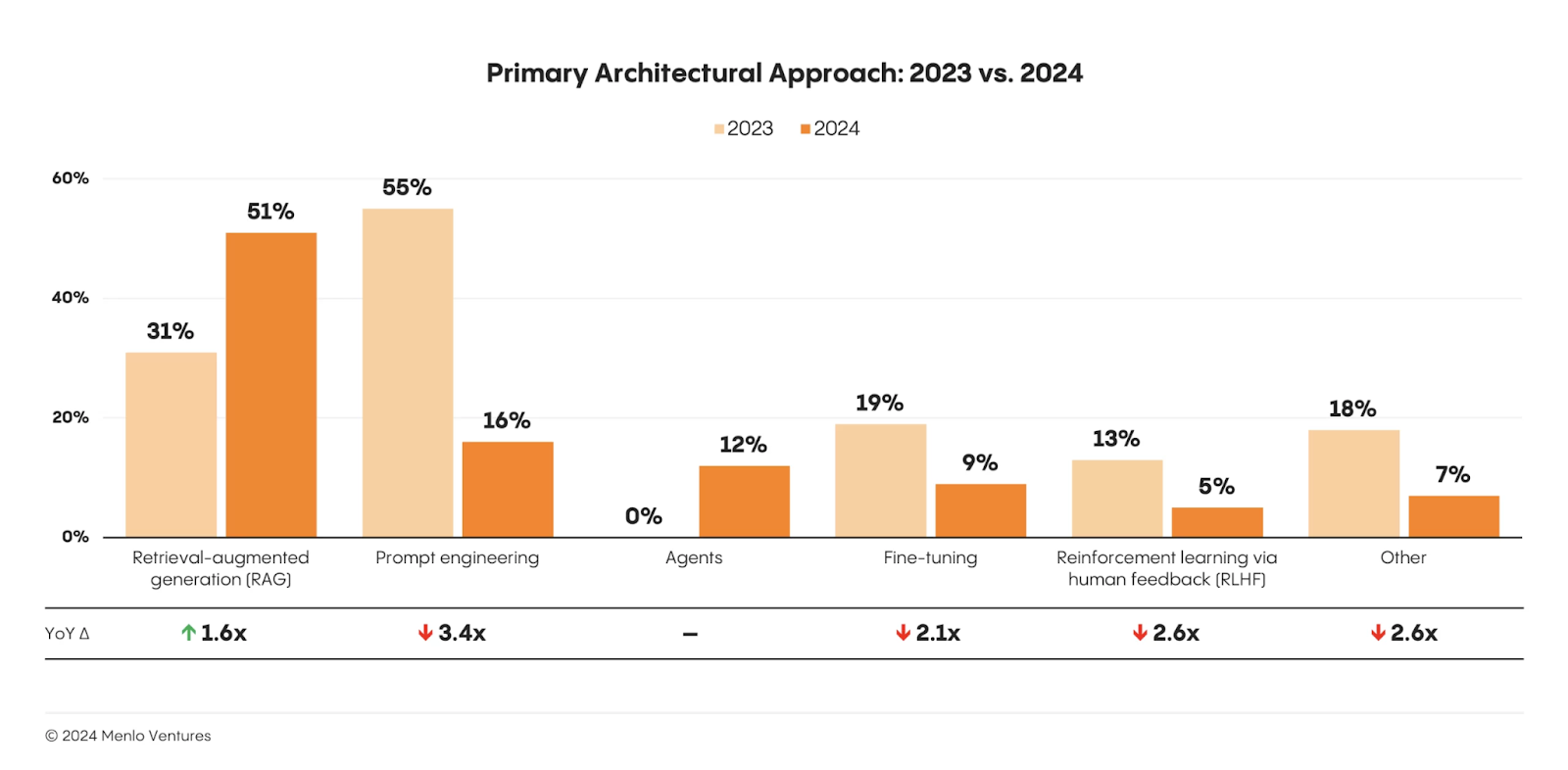
But RAG is a resource sink. It requires constant updates, drains time, energy, and budget (80% of token costs!). And still doesn’t guarantee the accuracy you need.
- RAG can’t give you a single source of truth. So you’re stuck verifying data to avoid inconsistencies or outdated info. Even then, GenAI might still deliver confident nonsense.
- It lacks built-in governance or security. Meaning, you’ll need strict access controls, constant monitoring, and sensitivity classifications to prevent data leaks.
- And the costs? They stack fast. RAG requires specialized skills: LLMs, vector databases, prompt engineering. Many companies have to hire just to get started. Add hosting vector databases and frequent API calls, and scaling your GenAI becomes expensive, fast.
- Then there’s the prompting strategy. Users rephrase questions and engineer clever inputs, hoping for reliable answers. But why should you need to be a “prompt houdini” just to get trustworthy results? Instead of making data easier to use, it complicates things, adding frustration and inefficiency at every step.
The Hidden Costs of GenAI Hallucinations
Hallucinations in GenAI can cause things to go sideways. And by sideways, we’re talking about losing a cool $100 billion in value. Yes, that happened.

Google’s parent company, Alphabet, took the hit last year after their chatbot confidently (and incorrectly) claimed that the James Webb Space Telescope (JWST) snapped the first image of a planet outside our solar system. Fun fact: that milestone happened 17 years earlier. Oops.
But it’s not just about embarrassing PR flubs or tanking stock prices. Hallucinations are sneakier than they look, and here’s why they’re an even bigger deal than you might think:
Incorrect GenAI Responses Lead to Costly Mistakes
GenAI hallucinations are a liability–especially for organizations where every decision impacts not just you but your partners, suppliers, and clients. When GenAI results veer off course, the effects can ripple through the entire ecosystem.
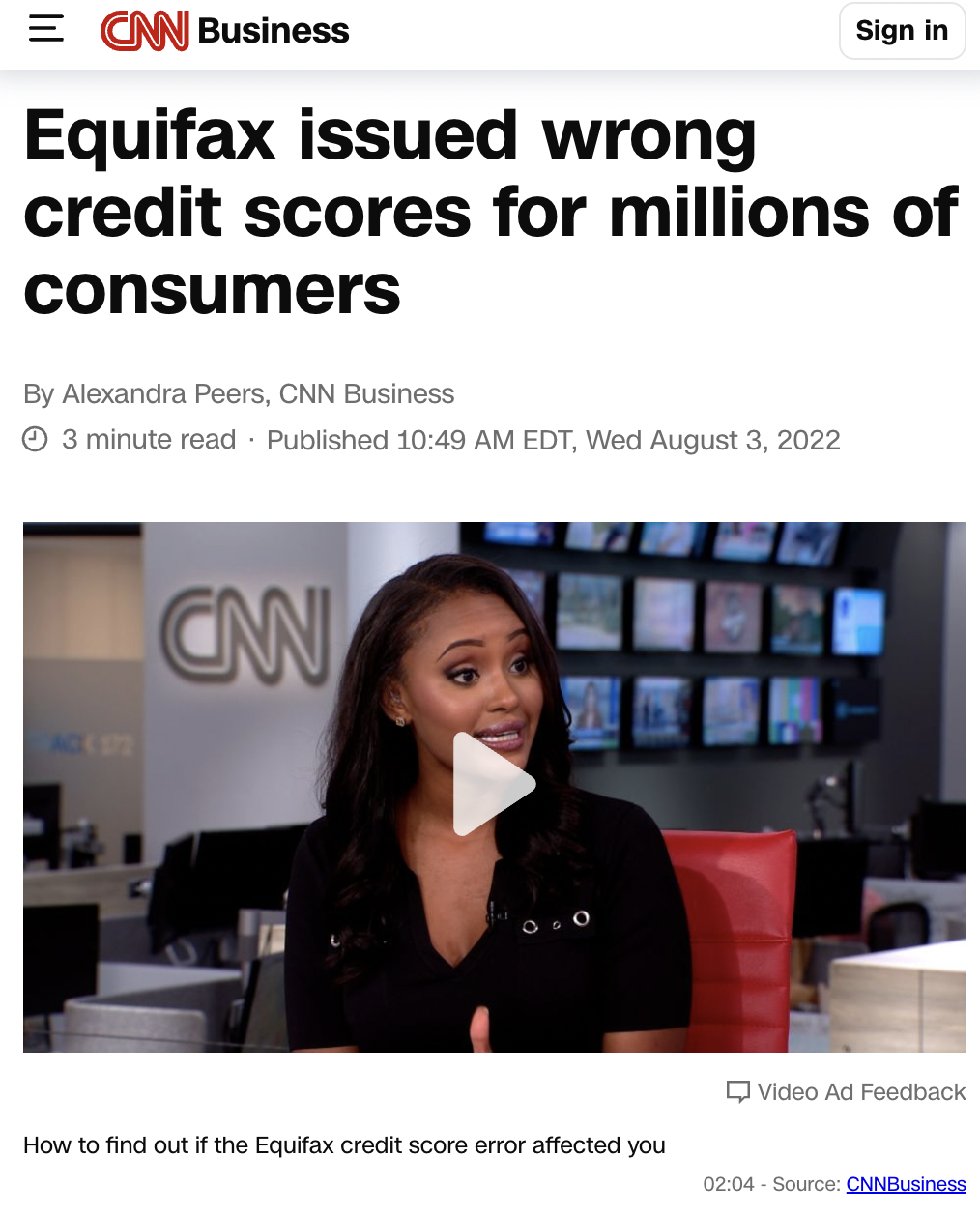
Just think of Equifax, who, back in 2022, issued inaccurate credit scores by 20-25 points for over 300,00 individuals. The cause was a “coding issue” within their legacy server, where specific attribute values were false. This cost Equifax 5% drop in their stock prices, and a class-action lawsuit.
Loss of Trust
Trust is everything when it comes to adopting enterprise GenAI. But hallucinations erode it fast. A recent McKinsey survey found that 63% of execs see inaccurate outputs as the biggest risk to their GenAI initiatives.
And it’s not just about the immediate fallout of a single hallucination. One bad result and your data teams start double-checking every answer manually, slowing processes to a crawl. Worse, leadership begins to question the ROI of the whole initiative. In fact, Gartner recently reported that nearly 50% of CIOs say that GenAI hasn’t met ROI expectations.
But the problem runs deeper. Without trust, data-driven cultures crumble. Employees doubt data-based insights. Adoption stalls. And GenAI’s potential? Left untapped.
Amplified Risks in Regulated Industries
GenAI and agentic analytics models bear risks for any industry. But highly regulated fields have zero tolerance for inaccuracies. Think fines for compliance breaches, lawsuits over bad reports, or worse, harm to customers. Hallucinations here are a much pricier problem.
The fix isn’t optional. Organizations must safeguard sensitive data with measures like encryption, access controls, and data sensitivity classifications to prevent breaches and leaks. Regulations like HIPAA (healthcare) and GDPR (privacy) demand it. Skip compliance, and you’re looking at operational delays, reputational hits, and fines that’ll make your CFO cry.
And now, the European Union’s AI Act has raised the stakes. It sorts AI systems by risk level:
- Unacceptable risk: Banned outright. Think manipulative AI or social scoring.
- High risk: Extra strict regulations and heavy oversight.
- Limited risk: Transparency rules for things like chatbots and deepfakes.
- Low risk: Free to play.
It puts the compliance load squarely on developers of high-risk AI, with extra rules for general-purpose AI. The bottom line? In the AI sandbox, you’d better play fair – or get booted out.
Strategies for Mitigating GenAI Hallucinations
So, how do you stop your enterprise GenAI from hallucinating?
The key lies in building a solid footing for your data and using methods that bridge the gap between GenAI and enterprise needs. Let’s see what these include.
Align Your Data and GenAI through Semantic Coherence
Think of semantic reconciliation as teaching GenAI to “speak fluent enterprise.” Add context and meaning to your data, and GenAI delivers answers that are accurate, relevant, and (your) business-ready.
Generative Semantic Fabric (GSF) takes this a step further. It creates a single source of truth – without moving or touching your data. Using only your metadata, it connects data through silos, departments, and tools. Every term, concept, and context stays clear, consistent, and aligned with your business logic.
Plus, GSF also builds workflows with human oversight. Certify results. Adjust the framework. Make it work for your company’s standards and needs. Simple and smart.
For more on the importance of semantics, check out this podcast with #TrueDataOps.
Augment Your Governance to Make Responses Trustworthy
Manual governance isn’t enough for GenAI. Accountability and transparency in every interaction with your chatbot is a must these days. And augmented governance does just that. This is all part of the Generative Semantic Fabric (GSF), built to make governance effortless and scalable. It also automates 90% of the heavy lifting, saving time and reducing errors.
Here’s what you can do with it:
- Auto-tag sensitive data: Automatically label and update PII and compliance tags, keeping your data accurate and secure. No manual effort needed.
- Proactive compliance monitoring: Spot risks early with real-time alerts and autogenerated lineage for quick fixes. Stay compliant and build trust.
- Auto-build your business glossary: Link business terms to data definitions effortlessly, keeping everyone’s on the same page while cutting governance workload.
- Auto-update documentation: Metadata relationships, hierarchies, and usage – documented and refreshed automatically.
With proactive, augmented governance, every GenAI query runs through a certified, auto-generated business glossary. Aligning goals, language, and compliance on the fly.
It turns GenAI from a black box into a transparent, governed system. Teams, stakeholders, and regulators? They’ll buy in with confidence.
Take Teva Pharmaceuticals, for example. Teva needed to govern massive smart device datasets without skyrocketing costs. With illumex and the Generative Semantic Fabric (GSF), they achieved:
- 90% less manual data handling,
- Seamless compliance across departments,
- A fully governed, AI-ready foundation – without heavy resource costs.
(If you’re curious, check out the full customer case study here)

Apply Active Metadata Management
Your business changes constantly. Your metadata (‘data about your data’) does too.
Active metadata management is all about good data hygiene and strong GenAI guardrails. It keeps your data fresh, relevant, and AI-ready. New datasets pop up, old ones evolve, and business priorities shift. Without active metadata, your GenAI falls behind, working with outdated data.
The thing is, GenAI doesn’t always play nice with traditional data management. It wasn’t designed to. The new tools thrive on fluid, contextual information. Legacy data systems? They were built for structure and consistency.
Most organizations struggle to find a way to integrate these two worlds effectively. That’s where active metadata management (a core part of GSF) steps in. Bridging the gap between the old and the new. It keeps your GenAI responses precise, adaptable, and always in sync with your business. At any scale.
Automate Context and Reasoning
Automating context and reasoning beats manual-heavy methods like RAG every time.
GSF is trained on ontologies specific to your field. It embeds semantic and graph models into your (meta)data, constantly retraining them on the ever-changing metadata flowing from your organizational systems.
It makes sure your data and GenAI speak your language. Real-world business terms, relationships unique to your company. It makes data interactions intuitive and natural – built to work the way people actually think and communicate. After all, you shouldn’t need to be a data wizard or a prompt guru to get value from your data.
GSF automates what would take months by hand. It reconciles data, aligns semantics, and embeds context and reasoning directly into your GenAI systems.
GSF slashes time, resources, and costs. It makes sure your GenAI gives you 100% governed, accurate answers.
Goodbye AI Hallucinations, Hello Reliable Enterprise GenAI
You don’t need to waste hours fine-tuning prompts, spend a fortune maintaining workarounds like RAG, or keep guessing which GenAI outputs are reliable.
illumex’ Generative Semantic Fabric automates semantic coherence, active metadata management, and augments your governance. It makes sure your GenAI works the way you need it to: accurate, accountable, and ready to deliver value at scale.
With illumex, your GenAI speaks your business’s language, stays up-to-date with evolving data, and builds trust into every decision.
Ready to see how your enterprise GenAI can stop guessing and start delivering? Book a demo today.



