


Data Lake / Mesh / Data Fabric and Everything in Between
My Impressions and Perspectives on the Gartner® Data & Analytics Summit 2023 – Part 3.
Contents of this blog series:
- Lead for Purpose. Connect with Trust. Make an Impact.
- Governance is Even a Hotter Topic in the Era of ChatGPT, and 12 Steps to Address Data Quality for Good.
- Data Lake / Mesh / Data Fabric and Everything in Between (The Active Metadata).
In the previous blog, I addressed how Governance prepares enterprises to achieve technological breakthroughs while maintaining quality. In this blog, I cover what feels to me like the dawn of a new era in Data Management: the rise of Active Metadata as a glue between different components and the enabler of Augmented Governance and Data Fabric/Data Mesh.
Gartner named the 2020s the “Era of Active Metadata” (as opposed to the 2010s being the “Era of LDW” and the 2000s the “Era of post-EDW”) [1]. Between Data Lake, Data Mesh, Data Fabric, DataOps, Metadata, and other popular buzzwords, and the rise of Generative AI tools, I feel it is hard for organizations to decide where to head first.
I summarized multiple sessions from the Gartner Data & Analytics Summit 2023 dealing with these Data Management topics to help you make sense of the definitions, implementations, pros and cons, long-term strategy and prioritization, etc.
But first thing’s first: what is the underlying Data infrastructure we will use in “the Era of Metadata”? I hope, by now, many of you will answer “data lake.”
Data Lake
“Avoid Data Lake Failures by Addressing Modern Lake Requirements” [2] was Donald Feinberg’s session about data lakes and how to make them work. With Donald’s recent announcement of his retirement, I was happy to have a chance to hear Donald this last time (for me) on a stage.
The Data Lake concept is not new, and we used to expect Apache Hadoop to be a kind of on-prem data lake, but, of course, with no ACID or governance. In my experience with Hadoop, it was mainly used for Data Science projects. According to the presentation, this was the typical use case. It is common knowledge that the majority of Hadoop installations didn’t work. With no curation, Hadoop is just a massive bag of files, and it requires talent to access the data from ETL or Business Intelligence Applications. So swamp it was.
Funnily enough, history still repeats itself: Data Lakes should have metadata, governance, and data zones to serve operational and analytic use cases. Otherwise, they quickly turn into swamps.
According to Don, if you are successful in your Data Lake implementation, you should expect exponential growth of use cases like Data Science, self-service, customer 360, warehousing, and reporting, to which you should prepare.
The preparation advice from Don was to use one cloud, not on-prem or multi-cloud.
Also, Data Lakes should have multiway collaborations between the D&A Center Of Excellence (Architect, Steward, DS/DE/MDM) and the functional units (citizen everything). You know all those horrific stories about different units “keeping their data to themselves” – this will not fly with a data lake.
So how do we facilitate the collaboration? Don says:
- “Curate your data lake- To assure required data is present, reduce data redundancy,enforce data standards and control data retention
- Govern the usage of the lake’s data – For business compliance, privacy and security
- Require diverse semantics (metadata, catalog, lineage) – As documentation of the lake’s data, to facilitate data exploration and reuse, plus avoid the swamp.”
Nothing lasts forever under the sun, and, as I learned, Data Lakes today are facing a plateau, approaching 20-25% of the Total Addressable Market using them successfully. So what is next after Data Lake? Lakehouse!
The Lakehouse: what is it? Lakehouse is an architecture that combines a warehouse and data lake on the same platform. If you implement it, plan to have lots of skilled talent to support it: from data architects and modelers to DE, and DataOps, from Semantic experts to DPM, Stewards, DS, and Business Analysts.
I know that Hadoop’s success implementation rates are in the low double digits, similar to Lakes. What should you do to increase your chances of ending up on this statistic’s positive side?
Don recommends:
- Focus on delivering business value: design your data lake for multiple use cases to achieve higher business value.
- Select data management tools to support many ingestion, refinement, processing and delivery methods.
- Evolve toward a data ecosystem: plan for changes and increases with all these and other data lake components.
- Staff and skill-up for the data lake: data product managers, data scientists and data engineering are high-profile.
- Make sure your lake doesn’t get muddy: curate, govern and secure the data allowed.
Donald chose a funny ending to his session by quoting his colleague Guido De Simoni: ”Metadata is the fish finder in Data Lakes.” If you do not understand what it means by now, keep reading until the “Active Metadata” section.
Now that we covered Data Lakes as the primary data infrastructure component of the modern data stack, let’s see how it connects to the rest of the elements in the Data Management puzzle.
Data Fabric
A Deep Dive on Data Fabric was provided by Ehtisham Zaidi during his session “The Practical Data Fabric — How to Architect the Next-Generation Data Management Design” [3].
As the famous Simon Sinek saying goes, “Let’s start with Why” – why do we need Data Fabric? According to Ehtisham Zaidi’s opening statement in this session, “Data Fabric Delivers integrated data to all data consumers.”

What is Data Fabric?
According to Ehtisham, “Data Fabric is not a single tool or technology. It is an emerging data management design for attaining flexible reusable and augmented data integration pipelines; that utilizes Knowledge Graphs, semantics and active metadata-based automation; in support of faster and, in some cases, automated data access and sharing; regardless of deployment options, use cases and/or architectural approaches.” Alternatively, “Data Fabric = Metadata Analysis + Recommendations. It acts as an intelligent orchestration engine.”
If you find it complicated, you are not alone: most of the summit’s attendees I had the privilege of speaking with, had not yet finalized their opinion on this approach.
The expected benefits from the Data Fabric implementation can sugarcoat this bitter pill of complexity (you might remember this quote from last year’s D&A Summit’s blog):
According to Ehtisham’s presentation, by 2025, “active metadata-assisted automated functions in the data fabric will:
- Reduce human effort in half
- And quadruple data utilization efficiency.”
To my best understanding, those benefits should spread throughout organizations: from facilitating self-service for business users, via improving efficiency levels of data teams, to the overall organization’s data literacy levels which will result in higher data asset utilization.
Ehtisham continued with nine practical steps for implementing Data Fabric: First and foremost, start by establishing a metadata collection, the same way we did for data decades ago. Without this collection, the tools for its management will not matter.
Ehtisham listed the following type of metadata:
- Technical (schemas, logs, data models)
- Operational (ETLs, lineage, performance)
- Business (ontology, taxonomy)
- Social (queries, views, tribal knowledge, feedback)
By observing and comparing those different types of metadata, you will be able to see the difference between planned to actual user behavior.
The second step of Data Fabric implementation is Metadata Activation. In the last couple of years, we have heard a lot of “Metadata Activation.” What is it?
In the diagram below, Ehtisham explained where Metadata Activation tools came into play – with alerts, recommendations, preparation, and orchestration. The current state is “sending alerts when things change.” Activating metadata is done by graph analysis and advice on handling exceptions.

Step 3: Create Knowledge Graphs and Enrich Them With Semantics:
“Most relationship insights are lost when using traditional Data Modeling and integration approaches […] Data Fabric presents multi-relationship data as knowledge graphs.” Here we see how Data Fabric and Metadata Activation leverage Knowledge Graphs as the recommended underlying technology.
Step 4: Use Recommendations from Data fabric for Automation:
Metadata Activation automation functionalities will include engagement through semantics and search, insights on anomalies and sensitive data tagging, and even auto-correction for schema drift and data sources prioritization.
Step 5: Explore Self-Service Orchestration Opportunities:
It is important to remember that full automation is not required for Data Fabric implementation, as Ehtisham Zaidi pointed: “A data fabric does not require data management optimization, but it does enable it —automation not required.” Therefore, you can achieve it even with current (partially automated) tools.
Step 6: Utilize DataOps to Streamline Data Integration Delivery:
Another term trending for the last couple of years is DataOps, and there is solid reason for that: case studies showed that “by 2025, a data engineering team guided by DataOps practices and tools will be 10x more productive than teams that are not.” Sounds worthwhile for further exploring! So what is DataOps?
DataOps is a combination of Data Orchestration, Data Observability, Test/Deployment Automation, Environment Configuration Management, Version Control, CI/CD/ Git/Jenkins. Just like Data Fabric, this is not a function to be obtained from a single tool or vendor but the assembly of the tools from the categories mentioned above.
Step 7: Deliver Integrated Data as a Data Product (or Mesh-Style Delivery) – When Ready:
In my opinion, the ultimate goal of everything discussed in this session was to build a reliable base that allows delivering Data Products for self-service consumption by different business domains. The operational model for such delivery could be “Hub and Spoke,” according to Ehtisham (step 8). It was referred to as a “franchise” in my previous blog. In this approach, the central team owns tech ownership, resource alignment, governance, and architecture, and the data products are used in business functions.
Ehtisham belongs to this rare type of person who combines a long-term strategic outlook with a very down to earth, practical approach to recommendations, but you probably know that if you had the chance to talk to him even once. He continued with the last and most important step 9 with three paths of taking Data Fabric to production: the foundational path, the advanced path, and the automation path, based on the organization’s level of familiarity with data and business questions to be asked:
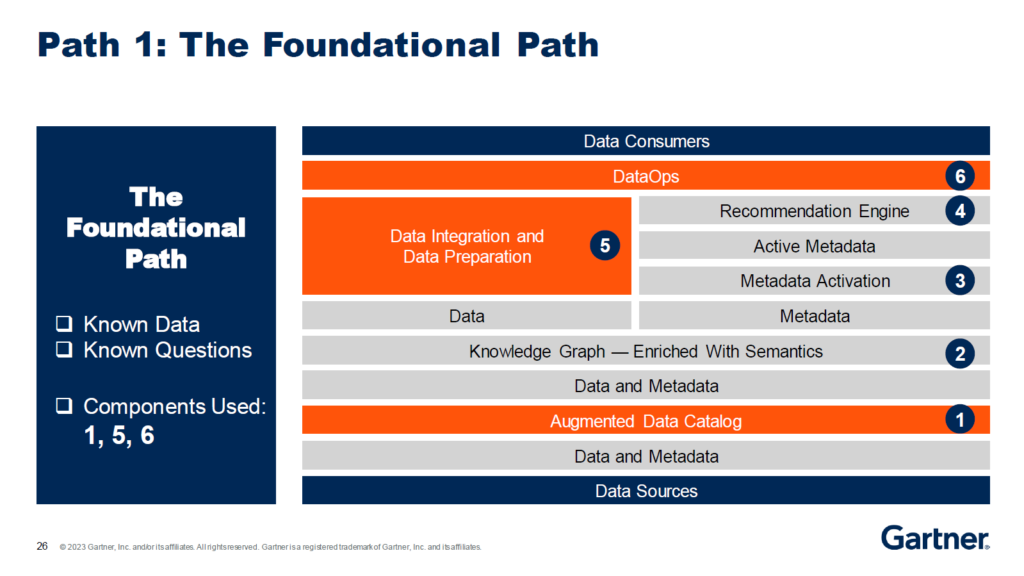


If I try to wrap my head around Ehtisham Zaidi’s session, those major points pop up:
- Do not expect to “buy” Data Fabric – a conceptual framework from mostly new technology solutions with a high degree of automation.
- Activate your Metadata, but first, collect it!
- Your implementation plan should include acquisitions of skills to leverage the DataOps.
But how can we talk about Data Fabric for this long without mentioning Data Mesh? It seems to be a strongly polarizing argument in the community about those somewhat conflicting approaches. I’m strongly biased here, and you might feel it is coming through the summary of this part below.
Data Fabric or Data Mesh: Deciding Your Future Data Management Architecture
Robert Thanaraj and Ehtisham Zaidi joined forces for that session (“Data Fabric or Data Mesh: Debate on Deciding Your Future Data Management Architecture”), which was spectacular [1].
According to the session opening, we can say in retrospect that data architecture evolution achieved the 3rd stage of the “Active Metadata Era” in the 2020s, after going through the “LDW Era” in the 2010s and the “Post EDW Era in the 2000s.” This evolution allowed to deliver fragmented analytics initially, but then unified and, finally, augmented.
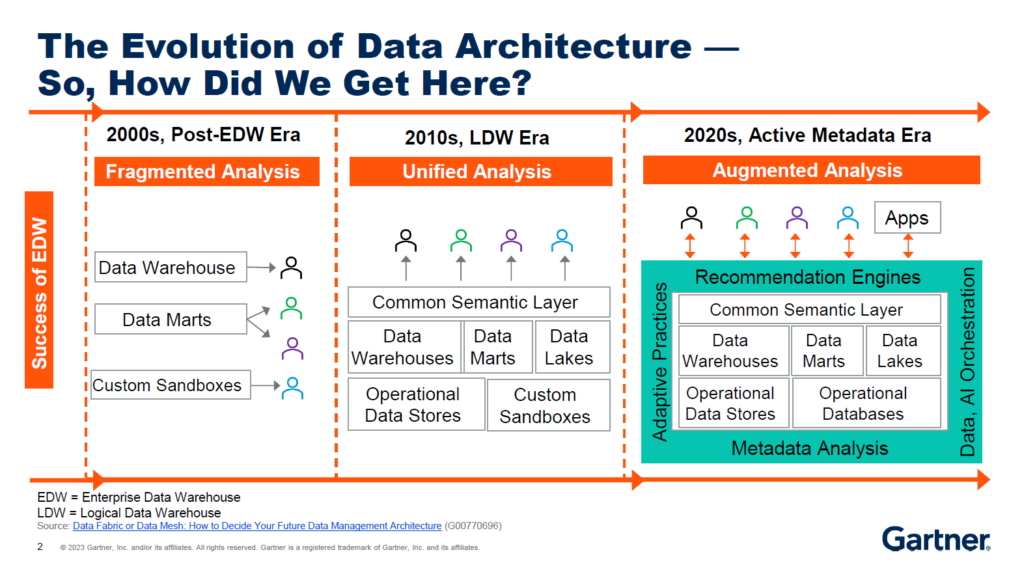
While most organizations face the decision to adopt either the Data Mesh or the Data Fabric concept, it is worthwhile to remember, as the speakers reminded, the Gartner’s 2022 Hype Cycle for Data Management, in which Data Mesh appears as “Obsolete Before Plateau” and Data Fabric just passed the “Peak of Inflated Expectations” into the “Trough of Disillusionment.” Not the best outlook, would you agree?
On the other hand, Data Fabric’s benefit is rated as “transformation,” with emerging tech maturity, 1-5% target audience market penetration and 5-10 years until mainstream adoption.
The slide below shows the technology pillars for a Data Fabric implementation color-coded from green for maturity to yellow for emerging to red for the most novel functionality.

For the remaining part of the session, the speakers stressed the “co-pilot” nature of data fabric for data teams and the confidence it gives business users for their self-service.
And now to Data Mesh: Data Mesh is NOT an established best practice; it is rather an emerging data management approach, which is a domain-led practice (data is managed and governed by SMEs within domain teams) for defining, delivering, maintaining and governing data products (flexible, reusable and augmented data artifacts).
Or, in other words:

Gartner’s evaluation of Data Mesh’s benefit is rated as “low,” with low tech maturity, 1-5% target audience market penetration, and is predicted to become obsolete before plateauing and being absorbed by other products or approaches, as Robert Thanaraj and Ehtisham Zaidi presented.
The pros of Mesh include, according to Robert’s take, consumption readiness, approval for use by custodians via a marketplace, self-served to a data products consumer, audited by subject owners, and life cycle managed by a data product manager. To me, it sounds similar enough to the original definitions in the Mesh “Bible” on Medium.
With all the cons and risks detailed above, why do organizations explore Data Mesh as a valid possibility for their data management practice?
The reasons, as I understand them, are:
- Failed deployments frequently jeopardize centralized setup.
- Competing urgent business priorities – bypass IT for speed and scale by implementing mesh within business functions.
- Quick access for a citizen analysts self-service.
- Overcoming spaghetti-like point-to-point integrations.
Robert and Ehtisham shared statistics from a survey conducted by Gartner:
- Most organizations let IT implement Mesh
- 80% are not comfortable with governance implementation at the domain level
- Another risk – Data Mesh implementation is consulting heavy
- The projects usually end up with a manual hard-coded Semantic Layer
After hearing all that during the session, I fail to see the difference between Mesh and implementing a data warehouse hard-coded Semantic Layer!
“The 2021 Gartner D&A Governance Survey indicated that only 18% of those surveyed said that their governance was mature and scaling across the enterprise. Those in this category reported far higher levels of overall success in achieving governance outcomes than the others.”
So, when should you use mesh? Only (!) when you have low metadata maturity and high governance maturity!!!
85% of organizations are low in both (!!!) So what can we do? Stick to the DW and start capturing metadata.
Pursuing Mesh with both “lows” will take you back to the 2000’s silos.
To conclude, the most important slide from this session:
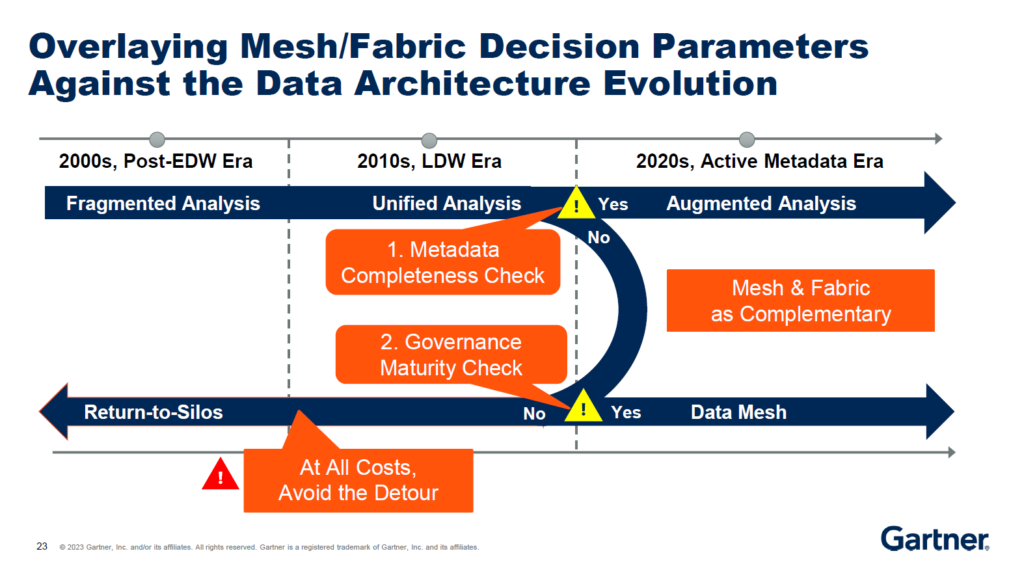
You might remember that Metadata was a common thread in every part of this blog – from the basics of where you should store data (central Data Lake), how to maximize its value (with Governance and curation), and whether to prioritize Data Mesh or Data Fabric framework. This clearly shows handling Metadata carefully and diligently is a must before spearheading the stormy and exciting waters of Data Fabric implementation.
The Active Metadata Helix: The Benefits of Automating Data Management
It is only natural to finish this part of my blog series with the wisdom of Mark Beyer, the biggest supporter of Metadata and its activation [4].
Let’s begin at the end: the key takeaway from this session was
“Metadata is abundant now. Start analyzing it and learning from it to invert your data management approach, from design-then-build to observe-then-leverage”.
And this is Mark’s repeated motto throughout the session: ”Stop designing, start observing.”
Mark also refreshed the definition of Metadata: It is a triplet of data with a subject (what brings these objects together?), an object (the column, attribute, tag of interest), and a predicate (explains what the subjects will do or have done to the object).
According to Mark, the logical conclusion of this triplet structure is that metadata should be managed and analyzed as a graph. He used the colorful expression to stress his point: “Metadata screams at you, ‘I am a graph!’”
But my favorite definition of Metadata (also from this session) is “Metadata is many partial reflections of data across cases, adding more metadata fills in gaps from the ‘real world.’”
I was curious about the session’s name right from the beginning. Helix? Combining Metadata forms a multilayered Helix. I will try to remember to use this new term. It definitely sounds fancy.
Every time you use data, you design it first, and then you run it. But what happens in reality rarely matches the design. Observation of metadata gives us the span of diversions.
This gives us the Active Metadata definition: “Active metadata is present when actions in one system result in changes in a second system and the analysis, recommendation, instructions, and response are all done via metadata.”
Mark’s straightforward recommendations on Metadata Activation sound easy, but believe me, if you don’t have the right tool, they are not: Here are three actions based on the explanation above to plan when you get back to the office:
- Capture-capture-capture metadata and accumulate it;
- Analyze metadata using graphs;
- Implement an alert system to data producers and consumers based on changes in metadata;
Oh, boy! Kudos if you read this sentence. You survived this blog to the end!
I chose to combine the topics of Data Lake, Data Fabric, Data Mesh and Active Metadata since they all address the paradigm shift we have to face and address to enable the new reality discussed in the first blog and support the governance I covered in the second blog to make it trustworthy. In the last part of this blog series, I will cover the future of data business as it was discussed at the summit.
[1] Gartner, “Data Fabric or Data Mesh: Deciding Your Future Data Management Architecture,” Gartner Data & Analytics Summit, Orlando, Florida, 20-22 March, 2023.
[2] Gartner, “Avoid Data Lake Failures by Addressing Modern Lake Requirements,” Gartner Data & Analytics Summit, Orlando, Florida, 20-22 March, 2023.
[3] Gartner, “The Practical Data Fabric —How to Architect the Next-Generation Data Management Design,” Gartner Data & Analytics Summit, Orlando, Florida, 20-22 March, 2023.
[4] Gartner, “The Active Metadata Helix: The Benefits of Automating Data Management,” Gartner Data & Analytics Summit, Orlando, Florida, 20-22 March, 2023.
* GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.



